컬렉션 API 중, map이나 filter같은 함수는 결과 컬렉션을 즉시 생성한다.
이는, 컬렉션 함수를 연쇄하면 매 단계마다 중간 계산 결과를 새로운 컬렉션에 임시로 저장하고 있다는 것이다.
반면에, 시퀀스(Sequence)를 사용하면, 중간 임시 컬렉션을 사용하지 않고도 컬렉션 연산을 연쇄할 수 있다.
간단한 예로, 성이 ‘김’씨인 사람만 추려내는 예제를 살펴보도록 하겠다.
/* 김씨인 사람만 추리기 */
people.map(Person::name).filter {it.startsWith("김")}코틀린 레퍼런스 문서에는 filter와 map이 List를 반환한다고 명시되어있다.
이 말은 이 연쇄 호출이 List를 총 2개 만든다는 것을 알 수 있다.
한 리스트는 map의 결과를 담고, 다른 하나는 filter의 결과를 담는 것이다.
원본 리스트의 원소 갯수가 적다면, 리스트가 2개정도 더 생겨도 큰 문제가 되지 않지만, 만약 원소의 개수가 수천~수백만 개가 된다면 효율이 현저히 떨어질 것이다.
그렇기 때문에, 더 효율적인 결과를 만들기 위해서는 각 연산이 컬렉션을 직접 사용하는 대신 시퀀스를 사용하게 만들어 줘야한다.
people.asSequence() // 원본 컬렉션을 시퀀스로 변환한다.
.map(Person::name)
.filter { it.startWith("김") }
.toList() // 결과 시퀀스를 다시 리스트로 변환한다.전체 연산을 수행하면서 중간 결과를 저장하는 컬렉션이 생기지 않기 때문에, 원소가 아무리 많은 경우에도 성능이 눈에 띄게 좋아진다.
Sequence의 강점은 원소가 필요할 때 계산이 되기 때문에, 중간 처리 결과를 저장하지 않고도 연산을 연쇄적으로 적용해서 효율적으로 계산을 수행할 수 있다.
asSequence 확장 함수를 호출하면 어떤 컬렉션이든 시퀀스로 바꿀 수 있고, 시퀀스를 리스트로 만들 때는 toList를 사용한다.
그런데 왜, 시퀀스를 다시 컬렉션으로 되돌려야 할까?
컬렉션보다 시퀀스가 훨씬 더 좋다면, 그냥 시퀀스를 쓰는 편이 더 좋은거 아닐까?
이유는, 시퀀스의 원소를 차례대로 이터레이션 해야 한다면 시퀀스를 직접 사용해도 되지만, 시퀀스 원소를 인덱스를 통해 접하는 등의 다른 API 메소드가가 필요하게 된다면, 시퀀스를 리스트로 변환해서 사용해야하기 때문이다.
시퀀스 연산 실행: 중간 연산과 최종 연산
시퀀스에 대한 연산은 중간(intermediate)연산과 최종(terminal) 연산으로 나뉜다.
- 중간 연산(Intermediate): 다른 시퀀스를 반환.
- 최종 연산(Terminal): 결과를 반환
결과는, 최초 컬렉션에 대해 변환을 적용한 시퀀스로부터 일련의 계산을 수행해 얻을 수 있는 컬렉션이나 원소, 숫자 또는 객체이다.
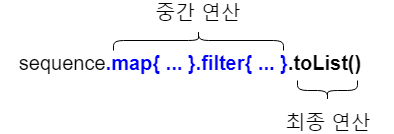
중간 연산은 항상 지연 계산(lazy)되며, 최종 연산을 호출하였을 때 비로소 모든 계산이 수행된다.
/* without terminal operation */
listOf(1,2,3,4)
.asSequence()
.map {
println("map: $it")
it * it
}
.filter {
println("filter: $it")
it > 5
} 위의 코드를 실행하면 아무런 내용도 출력되지 않는다.
이유는, map과 filter 변환이 지연 계산되기 때문에, 위 코드는 결과를 얻을 필요가 있는 최종 연산이 호출될 때 비로소 적용이 되기 때문이다.
그럼 최종 연산이 호출되는 경우를 보자.
/* with terminal operation */
listOf(1,2,3,4)
.asSequence()
.map {
println("map: $it")
it * it
}
.filter {
println("filter: $it")
it > 5
}
.toList()
println("리스트 결과: $List")map : 1
filter : 1
map : 2
filter : 4
map : 3
filter : 9
map : 4
filter : 16
리스트 결과 : [9, 16]
최종연산인 toList()를 호출하면, 그 전까지 지연됐던 모든 계산들이 수행된다.
이 예제의 시퀀스 연산 순행 순서를 잘 봐야한다(진짜 중요)
map→filter→map→filter..의 순으로 진행된다!
만약 위 코드를 컬렉션으로 구현한다면, map함수를 각 원소에 대해 먼저 수행하여 새 컬렉션을 만들고, 그 컬렉션에 대해 다시 filter를 수행할 것이다.
/* with collection */
val list = listOf(1, 2, 3, 4)
.map {
print("map: $it")
it * it
}
.filter {
println("filter : $it")
it > 5
}
.toList()
println("리스트 결과: $List")map : 1
map : 2
map : 3
map : 4
filter : 1
filter : 4
filter : 9
filter : 16
리스트 결과 : [9, 16]
여기서는 저 위 Sequence 연산과 다르게 map연산을 완전히 다 수행한 이후 그 결과가 filter연산으로 넘어가는 것을 알 수 있다.
컬렉션을 사용하면, 리스트가 다른 리스트로 변환된 이후 그 리스트가 전체 다음 연산으로 넘어가게 된다. 반면에, 시퀀스의 경우 각 원소에 대해 순차적으로 하나씩 적용이 된다. (즉, 첫 번째 원소가 처리되고, 두 번째 원소가 처리되는 형태이다.)
연산의 수행 순서는 프로그램의 성능에도 영향을 끼칠 수가 있다.
예로, fruitList 라는 컬렉션이 있는데, 가격이 2000원 이하는 과일만 사고 싶다고 하겠다.
이를 처리하기 위해서는 각 과일의 가격으로 map을 한 다음에 2000원 초과인 과일을 제외시켜야 한다. 이 경우, map다음에 filter를 하는 경우와 filter 후에 map을 하는 경우가 결과는 같아도 수행해야하는 변환의 횟수에서 크게 차이가 나게 된다.
컬렉션의 크기가 크다면, 이 차이는 성능상 이슈가 될 여지가 충분하다.
class Fruit(val name:String, val price: Int)
fun main() {
val fruitList = listOf(Fruit("바나나",1600), Fruit("사과",1800), Fruit("한라봉",3500),
Fruit("체리",2100), Fruit("파인애플", 2000))
// map 다음에 filter 수행
println(fruitList.asSequence()
.map(Fruit::price)
.filter{it <= 2000}
.toList())
// >>> [1600, 1800, 2000]
// filter 다음에 map 수행
println(fruitList.asSequence()
.filter{it.price<=2000}
.map(Fruit::price)
.toList())
// >>> [1600, 1800, 2000]
}

위 그림과 같이, map을 먼저 하게 되면 모든 원소를 이터레이션 하게 된다.
반면에 filter를 먼저 하게되면 조건에 맞는 원소만 이터레이션 하기 때문에, 성능상 더 효율적인 이점이 있다.
시퀀스 만들기: asSequence(), generateSequence()
지금까지 살펴본 시퀀스 예제는 모두 컬렉션에 대해 asSequence()를 호출해서 만들었다.
시퀀스를 만드는 다른 방법으로는 generateSequence()가 있다.
이 메서드는 이전의 원소를 인자로 받아, 다음 원소를 계산하는 방식으로 동작한다.
fun main() {
val numbers= generateSequence(0) { it + 1}
val numbersTo100 = numbers.takeWhile{ it <= 100}
println(numbersTo100.sum()) // 모든 연산은 "sum()"(최종연산)이 호출될 때 수행된다.
// >>> 5050
}
Uploaded by N2T
'Kotlin > Basic' 카테고리의 다른 글
| [Kotlin] 내부(Inner class)와 중첩 클래스(Nested class) (0) | 2023.01.11 |
|---|---|
| [Kotlin] 더블콜론(::) 참조 (0) | 2023.01.10 |
| [kotlin]코틀린의 생성자(constructor) (0) | 2023.01.05 |
| [Kotlin] Scope Functions 정리 (0) | 2023.01.02 |
| [Kotlin] 클래스 계층 정의 (0) | 2022.12.31 |